TL
20/08/10 TL. Logical Regression, Airbnb 데이터셋 분석
- -
오늘 할 일
React 및 React-Native 공부
coursera - logical regression
모각코 회의
airbnb 데이터셋 분석
내일 할 일
연구주제 미팅
airbnb 데이터셋 실습
Fitting Room 좌표 - 실루엣부 구현 완료
React 및 React-Native 공부
영어공부 꼭!!!
-----------------------------------------------------------------
선형 회귀를 classification 문제에 적용하는 건 그리 좋은 방법은 아니다.
임계점을 기준으로 구분하기 때문에 오류를 낼 수도 있다.
classfication에서 결과 값이 0 or 1일 지라도, 가설에서는 0보다 작거나 1보다 클 수도 있다.
Linear Regression 에선
h(x) = Θ^T * x
Logistic Regression : h(x)가 0과 1 사이의 값으로 가도록 해줌.
h(x) = g(Θ^T * x) = g(z)
sigmoid function : g(z) = 1 /( 1+ e^(-z))
logistic function = sigmoid function
=>둘 다 g를 가리킬 수 있다.
추가로 추가된 x에서 y가 1일 수 있는 가능성으로 여길 것
y = 0 or 1인 상황에서
P(y=1| x;Θ) + P(y=0|x;Θ) = 1이다.
선형 회귀를 classification 문제에 적용하는 건 그리 좋은 방법은 아니다.
임계점을 기준으로 구분하기 때문에 오류를 낼 수도 있다.
classfication에서 결과 값이 0 or 1일 지라도, 가설에서는 0보다 작거나 1보다 클 수도 있다.
=> y = 0.5를 지나고 0 < y < 1인 sigmoid function을 적용한 Logistic Regression 사용.
Linear Regression 에선
h(x) = Θ^T * x
Logistic Regression : h(x)가 0과 1 사이의 값으로 가도록 해줌.
h(x) = g(Θ^T * x) = g(z)
sigmoid function : g(z) = 1 /( 1+ e^(-z))
logistic function = sigmoid function
=>둘 다 g를 가리킬 수 있다.
추가로 추가된 x에서 y가 1일 수 있는 가능성으로 여길 것
y = 0 or 1인 상황에서
P(y=1| x;Θ) + P(y=0|x;Θ) = 1이다.
---------------------------------------------------------------------------------
sigmoid를 참고해서, y = 0 or 1일 때.
y = 1 -> h(x) >= 0.5 -> (Θ^T)*x >= 0.
h(x) = g((Θ^T)*x) >= 0.5에서 x가 (Θ^T)*x인 걸 참고.
y = 0 -> h(x) < 0.5 -> (Θ^T)*x < 0
y가 0이될지 1이될지를 가르는 경계를 decision boundary라고 부른다.
-------------------------------------------------------------------------------------

데이터를 우선 들여다 봐서, encoding 대상인 object값들을 들여다 본다.
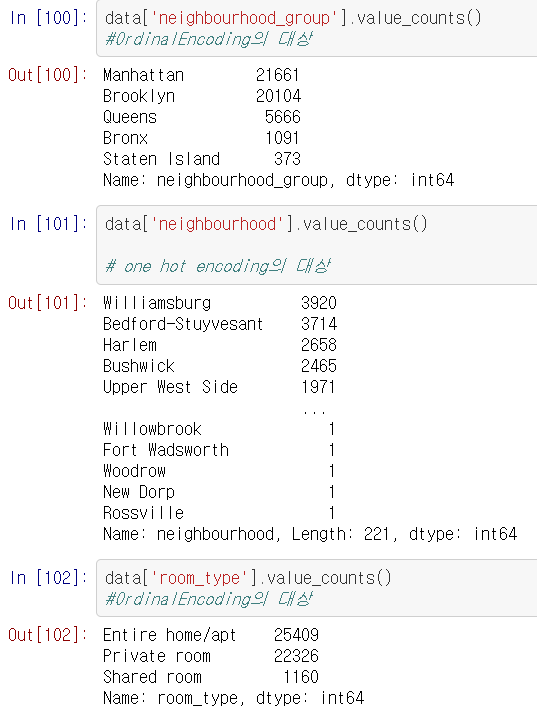
데이터를 들여다 보고 어떤 식으로 encoding할지 결정한다. 개수가 적은 것들은 Ordinal, 개수가 많은 것들은 one-hot으로 처리한다.



NAN 말고도 ""로 값이 들어있다면 NAN과 다를 바가 없으니 확인을 해봄
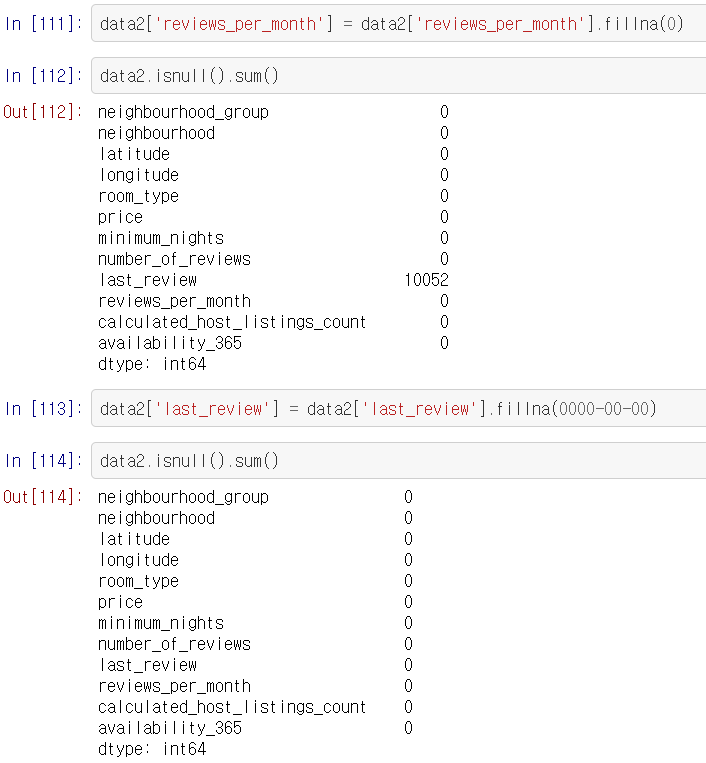
df.fillna()함수를 이용해 결측값을 채움.
https://rfriend.tistory.com/262
[Python pandas] 결측값 채우기, 결측값 대체하기, 결측값 처리 (filling missing value, imputation of missing valu
지난번 포스팅에서는 결측값 여부 확인, 결측값 개수 세기 등을 해보았습니다. 이번 포스팅에서는 결측값을 채우고 대체하는 다양한 방법들로서, - 결측값을 특정 값으로 채우기 (replace missi
rfriend.tistory.com
참고 블로그
df.fillna(df.mean()),
df.where(pd.notnull(df), df.mean(), axis='columns')
같은 방식을 이용하면 평균값으로 결측값을 채워줄 수 있다.

날짜를 나누는데, 일정한 형태로 나누어서 넣는다.
[Pandas] 일자와 시간(dt) 처리법
Pandas를 이용하여 일자와 시간을 처리하는 방법에 대해서 알아보겠습니다.Pandas에서 지원하는 일자시간...
blog.naver.com
를 참고. to_datetime()으로 String을 datetime64 타입으로 변경하면 다양한 추가 정보를 이용할 수 있다.
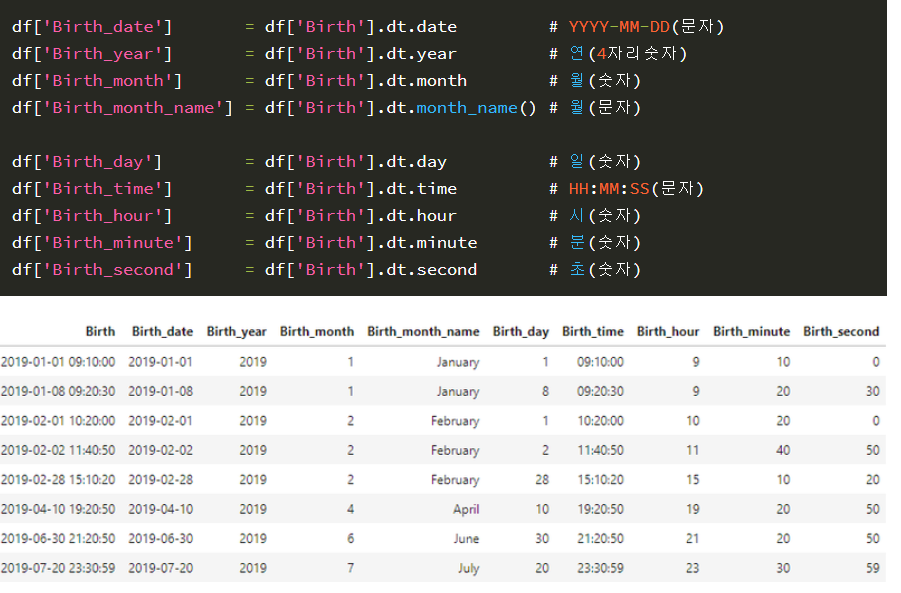
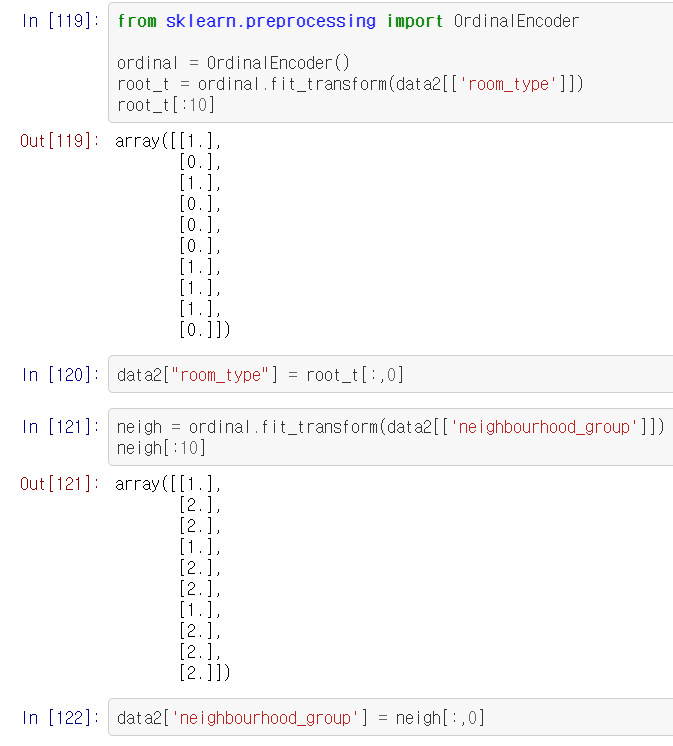
인코딩을 해준 다음, 값을 집어 넣는다. 나의 경우에는 값을 넣을 때, 중간 과정을 거치지 않고 바로 넣었을 때 오류가 많이 발생했는데 다음부터는 이런 식으로 해봐야겠다.

[Tensorflow][기초] argmax , argmin함수 소개 및 실습
[Tensorflow][기초] argmax , argmin함수 소개 및 실습 원핫인코딩때문에 자주 사용하게 되는 argmax 함수...
blog.naver.com
argmax는 원핫 인코딩에 주로 쓰인다.
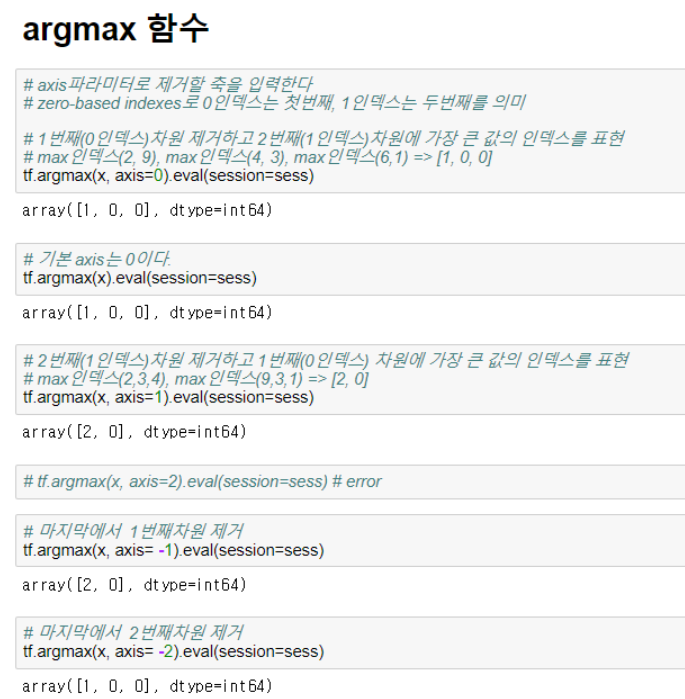
reshape는 기존 데이터를 차원과 형상만 바꿔준다.
[Python][Numpy] Reshape함수
기존 데이터는 유지하고 차원과 형상을 바꾸는데 사용하는 Reshape함수에 대해서 알아보자파라미터로 입력...
blog.naver.com
파라미터로 입력한 차원에 맞게 변경한다. -1로 설정하면 나머지를 자동으로 맞춘다.
예) (100,) -> (2, 50) : 변환 가능
예) (100,) -> (2, -1) : 1차원은 2로 지정하고 2차원은 자동이므로 50이 된다
바꾸는 개수가 나눠지지 않는다면 아래와 같은 오류가 발생하므로 주의한다.
예) (100,) -> (3, -1) : 1차원은 3으로 지정되지만 100을 3으로 나누면 1이 남아 아래 오류 발생
ValueError: cannot reshape array of size
그러면 여러 번 차원을 이리 저리 변경해도 처음과 값이 같을까 ?
정답은 order만 같게 해준다면 같다
따라서 order 파라미터 지정에 주의해야한다
order파라미터는 지정된 Index 순서에 따라 형상을 변환한다
=> 블로그 내용 중
여기서 종종이는 n X 1 로 만든 것이다.

이제 데이터의 상관 관계도를 보고 가격과 상관있는 순서대로 정렬해 준다.
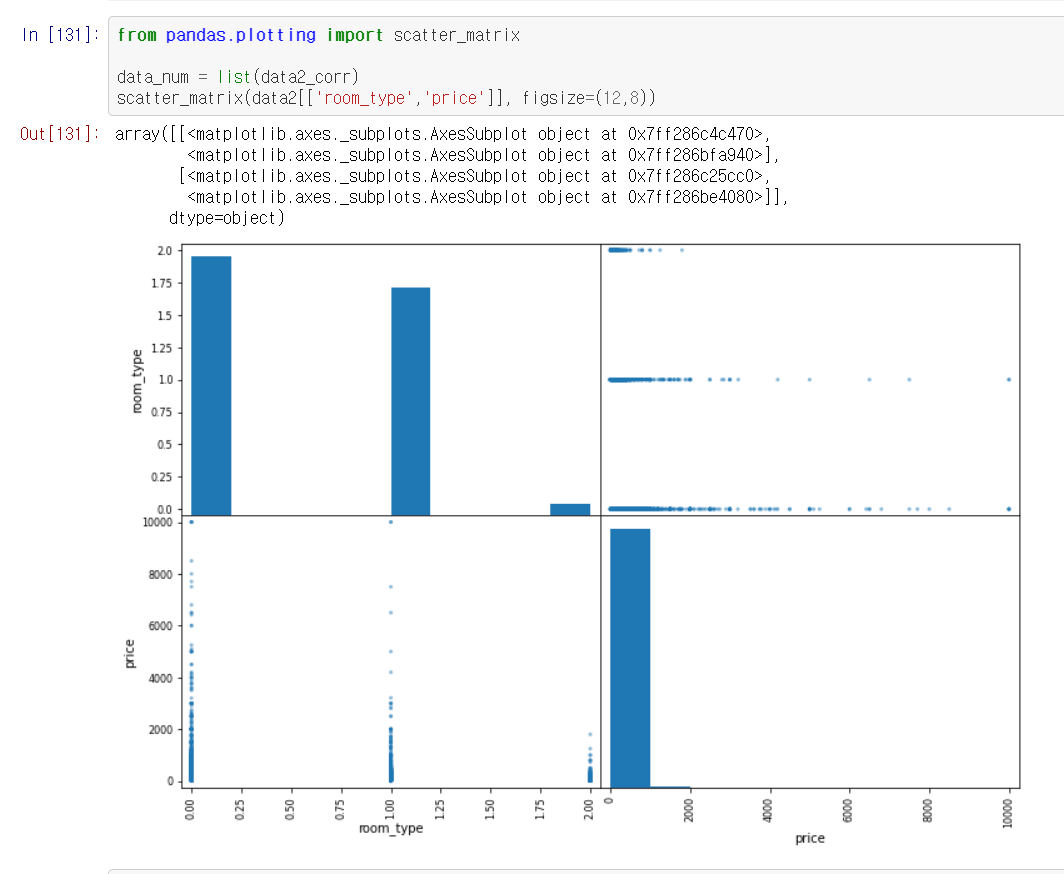
room type과의 관계를 가시적으로 본다. 전혀 관계가 없는걸 확인.

LinearRegression과 RandomForestRegressor를 이용해서 모델 점수 확인.

cross_val_score는 왜 과대적합이라고 판단한 걸까?

'TL' 카테고리의 다른 글
| 20/08/12 TL. Scrapy (0) | 2020.08.12 |
|---|---|
| 20/08/11 TL (5) | 2020.08.11 |
| 20/08/09 TL (0) | 2020.08.09 |
| 20/08/08 TL (0) | 2020.08.08 |
| 20/08/06 TL. 선형회귀 복습 (0) | 2020.08.06 |
Contents
소중한 공감 감사합니다