개발일기
캐시와 레지스터, 이벤트 루프
- -
계획
오늘 익힌 내용
캐시와 레지스터
레지스터는 CPU 요청 처리에 있어 필요한 데이터를 임시 저장하는 기억장치다. CPU에서 연산할 때 메모리에서 읽어오면 느리기 때문에 메모리의 데이터를 레지스터에 올려놓고, CPU에서 사용한다.

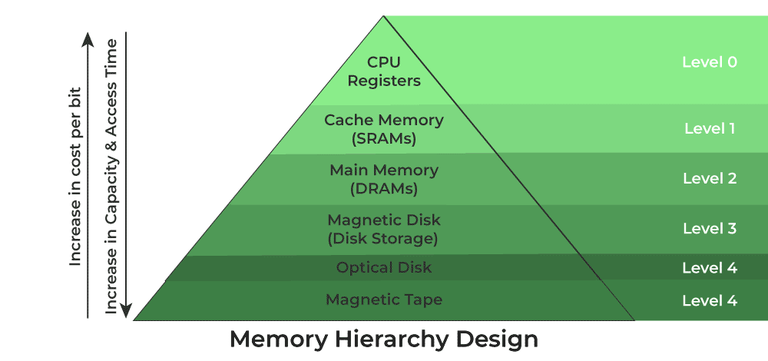
위 그림에서 보다시피, 레지스터는 Level 0에 속하고, RAM보다도 훨씬 빠르다.
레지스터는 일종의 캐시기 때문에 메모리에서 값을 때 적중률(hit ratio)를 올리기 위해 데이터 지역성을 고려해 값을 읽는다. 데이터 지역성에는 3가지 종류가 있다.
- 공간적 지역성 : 데이터를 읽을 때 주변에 있는 데이터들이 참조될 가능성이 높다.
- 시간적 지역성 : 최근 사용된 데이터가 재사용될 가능성이 높다.
- 순차적 지역성 : 기억장치에 저장된 순서대로 읽힐 가능성이 높다.
quick sort의 경우 best case에 O(nlogn)으로, merge sort와 수치상으로 같지만 best case시 더 빠른 성능이 나오는 이유도 공간적 지역성을 가지기 때문이다. 주위를 계속 읽기 때문에 연산시 page 변경이 적어 유리하다.
- cache hit : 액세스하려는 데이터가 이미 캐시에 적재되어 있는 상태
- cache miss : 액세스하려는 데이터가 캐시에 없어 읽어와야 하는 상태
- cache hit ratio : cache hit / cache access count
- miss ratio : 1 - cache hit ratio
캐시를 사용할 때 주의해야 할 점은, 원본 저장소에 있는 내용과 불일치하지 않게 정합성 관리를 해야한다는 것이다. 이를 위해 반영하기 위해 캐싱 전략들이 존재한다.
아래는 redis를 위한 cache 설계 지침인데, 다른 곳에서도 얼추 맞아서 가져와 봤다.
읽기 전략
- look aside : 데이터를 읽을 때 캐시를 우선 확인하고 캐시에 데이터가 없다면 DB에 질의하고 서버에서 캐시에 update한다
- 보편적인 방법이며, 동일 쿼리가 많은 경우에 유리하다
- read through : 캐시에서만 데이터를 읽으며, 데이터가 없을 경우 캐시에서 직접 DB와 동기화 한다
- connection을 아낄 수 있으며 캐시가 SPOF가 될 가능성이 높다.
쓰기 전략
- write back : 데이터 저장시 캐시에 저장해 놓고, 캐시에서 배치를 통해 DB에 저장한다.
- 캐시에서 오류 발생시 데이터 영구 소실한다.
- 캐시 내용을 파일 스토리지에 저장하면서 사용하면 어떨까?
- write through : cache에 저장하고 바로 db에 저장하는 전략
- 수정 요청이 적을 때 / 데이터 유실이 발생하면 안 되는 상황에 적합하다
- write back / write through는 자주 사용되지 않는 데이터가 저장되면 리소스가 낭비되므로 TTL을 꼭 사용한다
- write around : cache에는 write하지 않는다.
- db 데이터가 수정 / 삭제될 때마다 캐시를 삭제하던가, 캐시의 expire를 짧게 잡는다
- 데이터가 한 번 쓰이고 덜 자주 읽힐 때 좋다 (근데 그럴거면 캐시 왜 쓰지?)
조합
- look aside + write around : 가장 일반적인 조합
- read through + write around : 데이터 정합성에 안전
- read through + write through : 읽을 때 최신 데이터 보장, 쓸때 데이터 정합성 보장
참조한 블로그 중 3번째 블로그는 나중에 다시 읽으면 좋을 것 같다.
참조
- https://inpa.tistory.com/entry/REDIS-%F0%9F%93%9A-%EC%BA%90%EC%8B%9CCache-%EC%84%A4%EA%B3%84-%EC%A0%84%EB%9E%B5-%EC%A7%80%EC%B9%A8-%EC%B4%9D%EC%A0%95%EB%A6%AC
- https://beenii.tistory.com/101
- https://hongjw1938.tistory.com/192#recentComments
이벤트 루프
이벤트 기반 병행성은 멀티 쓰레드 환경에서 락에 대한 어려움과, 쓰레드 스케줄링에 대해 제어할 수 없어 어떤 순서로 작업할지 예측할 수 없다는 어려움을 극복할 수 있게 만든다.
이벤트 기반 병행성이란, 이벤트가 발생하면 그 이벤트 종류를 파악한 후 I/O 요청 / 다른 이벤트 발생 등의 처리하는 걸 말한다.
이벤트 루프란 이벤트 기반 병행성을 해결하는 가장 고전적인 구조이다. 싱글 스레드 환경에서 while(1)처럼 루프를 계속 돌며 이벤트를 기다리다가, 이벤트 발생시 이벤트 핸들러를 매칭시키고 실행시킨다.
단일 스레드만을 사용하기 때문에 락에 대해 고려할 필요가 없어지고, 현재 어떤 쓰레드가 어떤 작업을 하고 있는지에 대해 고려할 필요도 사라진다.
그러나, 블로킹 작업이 수행된다면 락이 걸리는 것과 마찬가지이기 때문에 블로킹 콜이 생겨선 안된다. 따라서 논 블로킹을 도입하게 되었다.
개인적으로 command 요청은 논블로킹, query 작업은 블로킹하는 식으로 처리되어야 하는 거 아닌가? 하는 생각이 좀 들었는데, query도 요청해 뒀다가 어떤 변수에 표시를 해놓는 다던가 인터럽트를 날린다던가 하는 식으로 처리하는 것 같다.
여태까지 Node.js에서 비동기 요청하면 이벤트 루프에서 워커 쓰레드를 생성하고 거기에 작업을 할당하는줄 알았다. 그런데 그게 아니였고, 워커 쓰레드는 그것과 별개로 다른 쓰레드를 할당시키는 구조이다.
libuv에서는 스레드풀을 할당해 놓고 비동기 요청을 받으면 거기서 처리하도록 만든다. 워커 쓰레드를 활용하는 것보다 훨씬 가벼운 요청이다.
이건 Node.js에서의 얘기고, 다른 이벤트 루프를 사용하는 툴들마다 다 구현이 다른 것 같다. 인터럽트를 사용할 수도 있고, 위처럼 스레드 풀이라던가 워커 스레드를 사용하기도 하는 것 같다.
참조
'개발일기' 카테고리의 다른 글
| Red Black Tree vs Heap vs AVL Tree (0) | 2023.08.17 |
|---|---|
| 입출력 장치와 Device Driver, Device Controller / 인터럽트 (0) | 2023.08.16 |
| 웹소켓과 폴링 (0) | 2023.08.08 |
| RAM에 Random이란 단어가 들어가는 이유 / Hash 공부(Java) (0) | 2023.08.07 |
| 영속성 전이 엔티티가 영속성 컨텍스트에 올라가는 순간 / lambda와 익명 객체와의 차이 / PO와 기획자의 차이 (0) | 2023.08.03 |
Contents
소중한 공감 감사합니다